pclean SLURM Submit Guide¶
Overview¶
pclean submit is the recommended way to run parallel cube imaging on
HPC clusters. It uses a two-layer SLURM job stack: one lightweight
coordinator job that hosts the Dask scheduler, and N worker jobs
spawned automatically via dask-jobqueue.SLURMCluster.
┌───────────────────────────────────────────────┐
│ Coordinator (SLURM job) │
│ • Hosts Dask scheduler │
│ • Partitions channels into sub-cubes │
│ • Dispatches tasks to workers │
│ • Concatenates sub-cube results │
│ │
│ sbatch → dask-jobqueue spawns: │
│ ┌────────────┐ ┌────────────┐ ┌───────────┐ │
│ │ Worker 0 │ │ Worker 1 │ │ Worker N │ │
│ │ (SLURM job)│ │ (SLURM job)│ │(SLURM job)│ │
│ │ sub-cube 0 │ │ sub-cube 1 │ │sub-cube N │ │
│ └────────────┘ └────────────┘ └───────────┘ │
└───────────────────────────────────────────────┘
Each worker images one sub-cube independently (embarrassingly parallel, no inter-worker communication). The coordinator partitions the frequency axis, submits Dask futures, waits for completion, and concatenates the sub-cube images into the final cube.
Quick Start¶
1. Write a YAML config¶
A minimal SLURM-enabled config needs cluster.type: slurm and the
slurm: / submit: sections. See
test_alma_pclean_v4.yaml
for a complete example.
2. Submit¶
pclean submit scripts/test_alma_pclean_v4.yaml
Output:
2026-03-12 05:24:08 INFO pclean.config Loading config from scripts/test_alma_pclean_v4.yaml
2026-03-12 05:24:08 INFO pclean.parallel.submit Wrote sbatch script to .../submit.sh
2026-03-12 05:24:08 INFO pclean.parallel.submit Submitted coordinator job 1631
Submitted coordinator job: 1631
3. Monitor¶
squeue --me
JOBID PARTITION USER STATE TIME NAME
1631 queue rxue RUNNING 0:13 test_alma_pclean_v4-coordinator
1632 queue rxue RUNNING 0:10 test_alma_pclean_v4-1
1633 queue rxue RUNNING 0:10 test_alma_pclean_v4-2
...
1647 queue rxue RUNNING 0:09 test_alma_pclean_v4-16
The coordinator job appears first (job 1631). Worker jobs are
auto-numbered (jobs 1632–1647, one per nworkers).
4. Override workdir¶
pclean submit scripts/test_alma_pclean_v4.yaml \
--workdir /scratch/cubeimaging/run_01
YAML Configuration Reference¶
cluster.slurm: — Worker SLURM Settings¶
These control each worker SLURM job (passed to
dask-jobqueue.SLURMCluster):
Field |
Default |
Purpose |
|---|---|---|
|
|
SLURM partition ( |
|
|
SLURM account ( |
|
|
Per-worker wall time ( |
|
|
Per-worker memory ( |
|
|
CPUs per worker; 1 is sufficient (CASA imaging is single-threaded) |
|
|
Worker job name base (auto-suffixed: |
|
|
Extra |
|
|
Python executable path on compute nodes |
|
|
Scratch directory on compute nodes |
|
|
Directory for worker stdout/stderr |
|
|
Shell commands before worker starts (e.g. |
cluster.submit: — Coordinator Job Settings¶
These control the coordinator sbatch script:
Field |
Default |
Purpose |
|---|---|---|
|
|
Working directory for imaging output |
|
|
Root of pclean pixi project (auto-detected from config path) |
|
|
Pixi environment to activate in the sbatch script |
|
|
Memory for the coordinator ( |
|
|
CPUs for the coordinator ( |
|
|
Wall time for the coordinator ( |
|
|
Job name (appears in |
|
|
Additional |
|
|
Log directory (fallback: |
|
|
Wrap run in |
cluster: — General Settings¶
Field |
Default |
Purpose |
|---|---|---|
|
|
Cluster backend: |
|
|
Enable parallel imaging |
|
|
Number of workers (= SLURM jobs in slurm mode) |
|
|
Channels per sub-cube ( |
|
|
Sub-cube concatenation: |
|
|
Keep individual sub-cube images after concatenation |
Example Config Walkthrough¶
From test_alma_pclean_v4.yaml:
cluster:
parallel: true
nworkers: 16 # 16 SLURM worker jobs
cube_chunksize: -1 # auto: 1000 ch / 16 = ~63 ch per worker
concat_mode: paged
keep_subcubes: false
type: slurm # use SLURM backend
slurm:
queue: queue # SLURM partition name
job_mem: 2GB # each worker gets 2 GB (128×128 images are small)
job_name: test_alma_pclean_v4
python: /path/to/.pixi/envs/forge/bin/python
submit:
workdir: /path/to/output/ # images written here
pixi_project_dir: /path/to/pclean/ # for pixi shell-hook activation
pixi_env: forge
coordinator_mem: 4G
coordinator_cpus: 2
coordinator_walltime: '24:00:00'
coordinator_job_name: test_alma_pclean_v4-coordinator
psrecord: true
The output cube (IRC+10216, SPW 25, 1000 channels at 128×128):
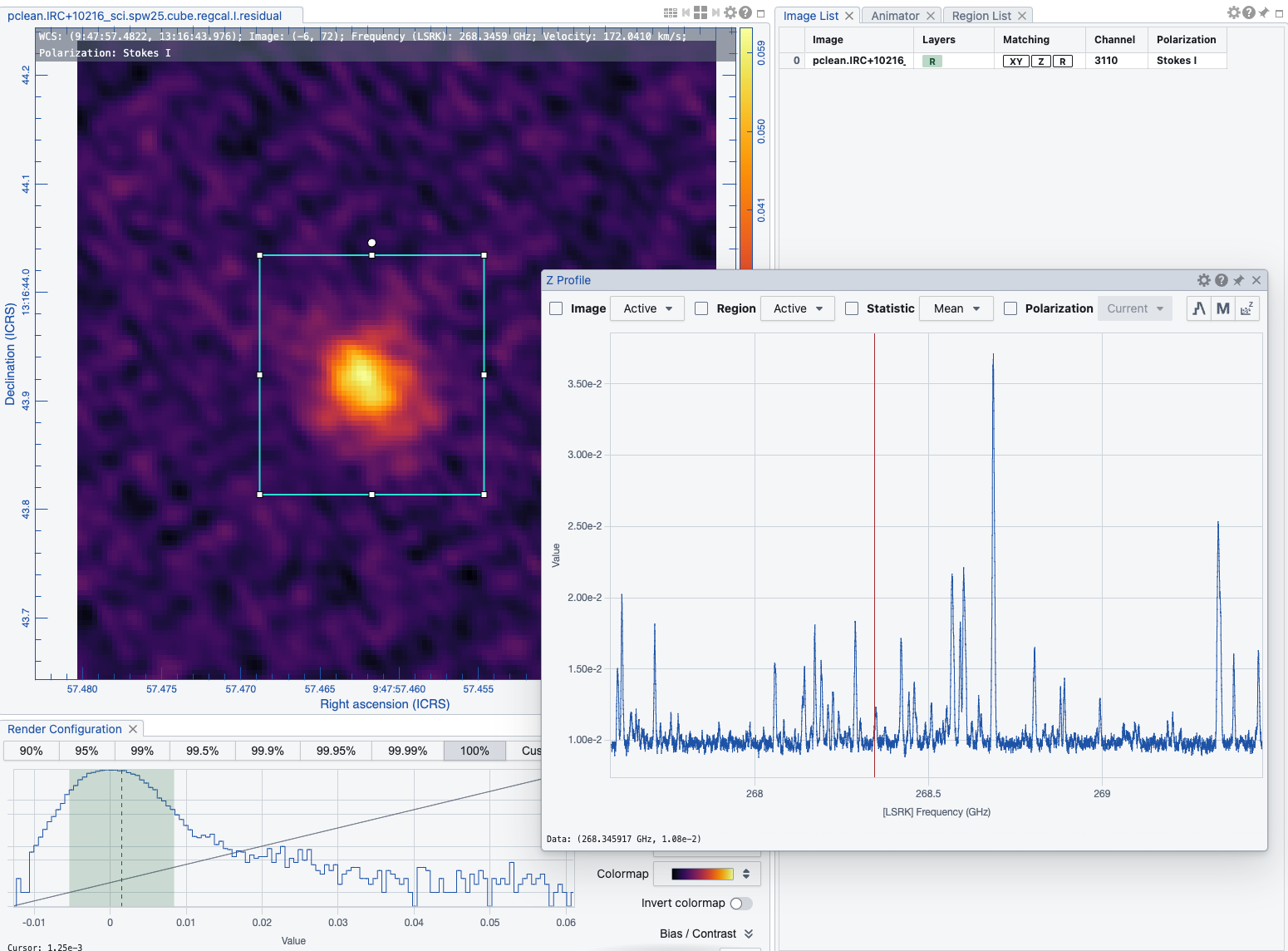
Sizing Guidelines¶
Resource |
Guideline |
|---|---|
|
Must fit CASA’s peak RSS for one sub-cube. Use |
|
The coordinator does no imaging — 4–8 GB is usually sufficient for Dask bookkeeping and final concatenation. |
|
Ideally |
|
Set generously; each worker images |
What pclean submit Does Internally¶
Loads config from the YAML file.
Generates sbatch script (
<workdir>/submit.sh) with coordinator SLURM directives, pixi environment activation, andpython -m pcleaninvocation (optionally wrapped inpsrecord).Calls
sbatchto submit the coordinator job.Coordinator runs on the allocated node:
Creates a
dask_jobqueue.SLURMClusterwith theslurm:settings.Calls
cluster.scale(jobs=nworkers)— each worker is a separate SLURM batch job.Partitions the frequency axis into sub-cubes.
Dispatches sub-cube imaging tasks via Dask futures.
Waits for completion, concatenates results.
SLURMCluster.close()cancels all worker jobs.
Cleanup¶
If the coordinator is killed abnormally (e.g. OOM, walltime), orphan worker jobs may remain. Clean them up with:
scancel --name=test_alma_pclean_v4 # cancel all workers by job_name
scancel <coordinator_job_id> # cancel the coordinator itself